A World Diffusion Model Criminally Undertrained
General ·Hillsbrad Diffusion
Recent world models like Genie demonstrate impressive capabilities in modeling game environments, but require massive amounts of training data and compute. Let’s see (qualitatively) what happens when we ignore those requirements…
The Setup
The approach uses:
- Just over 2 hours of 15FPS gameplay of World of Warcraft
- A pretrained Stable Diffusion autoencoder to obtain latent representations
- A denoiser trained from scratch, conditioned on a few player inputs (camera and character movement) and 10 previous frames via cross-attention
- 12-36 hours of an A100
Some expected outcomes:
- Simply reconstructing t-1 (local min)
- At best, remain stable for a few frames before degrading into a blur
- Minimal conditioning-adherence
Better than expected?
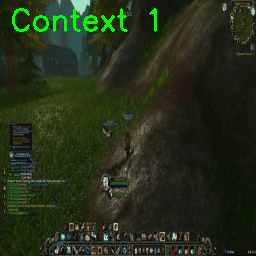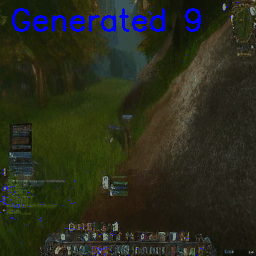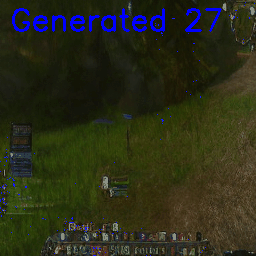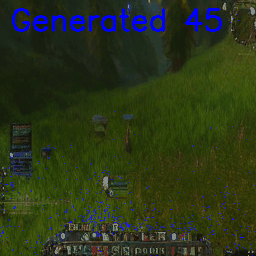
Foregoing the action conditioning for now, in the open-world the model:
- Generated coherent frames
- Maintained stability over multiple seconds
- Rather than collapsing, often settled into stable local minima (or, ‘gets stuck’)
Before getting stuck, the model might:
Morph the world by interpolating between different sections of the map (‘smooth’ interpolation)
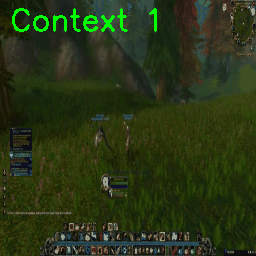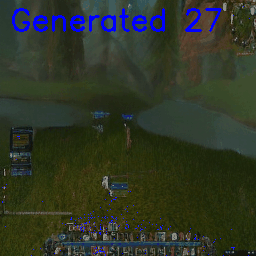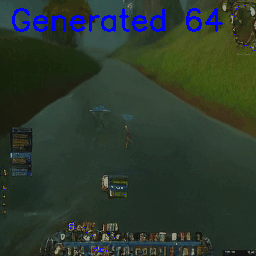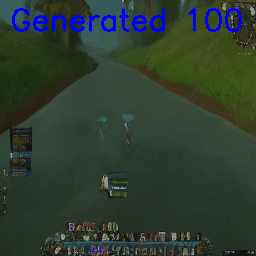
Or teleport into a different section of the map (abrupt interpolation between river and cave):
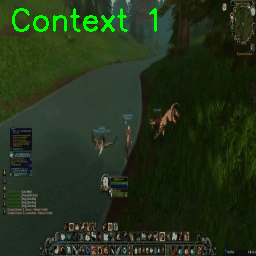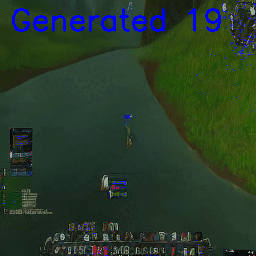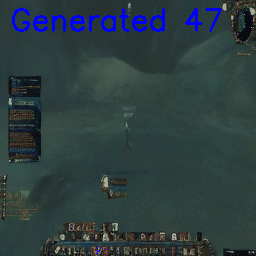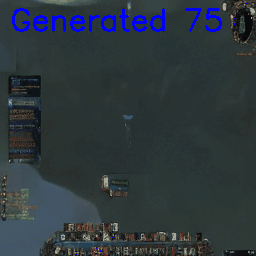
It’s interesting that already the user interface and world are modeled somewhat separately. Even though we’re already in the cave, only some frames later we can see the UI suddenly ‘snap’ to a different state.
We can see this property more clearly in another example. I did not condition the model on the inputs to open and close the inventory, so from the perspective of the model, this is a purely stochastic event. In some rollouts, it will on rare occasion open the inventory, and in others it will not. Note the bags on the right-side of the screen.It also ‘highlights’ the bags in the bottom-right in gold when opened:
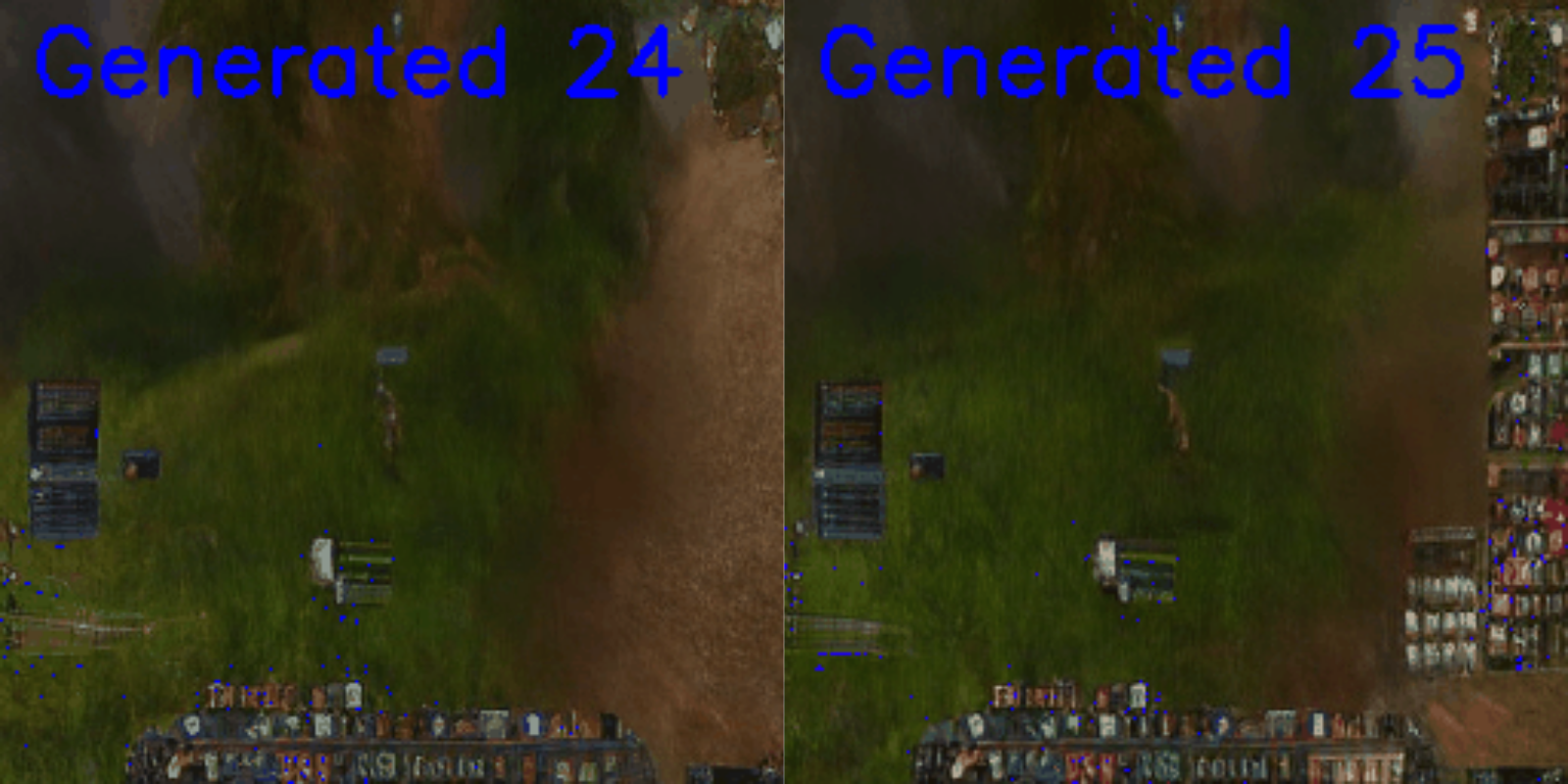
Although little-explored areas immediately degrade, like when briefly entering a house, funnily enough the model will sometimes take the easy way out and just delete the house entirely:
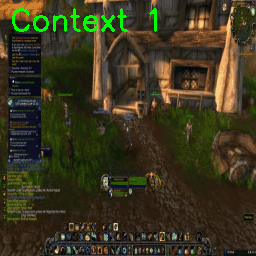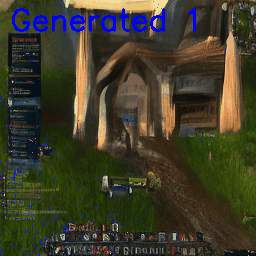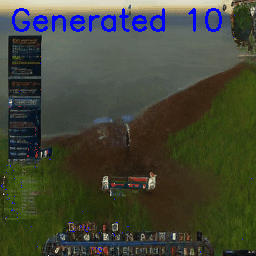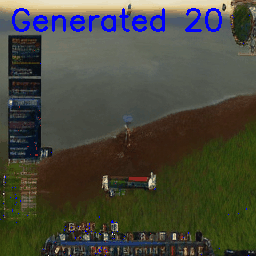
Looking a little closer, by frame 4 the top-left of the image is already sky or water and the model starts to interpolate into an ocean-watching episode. By frame 8, only a small section of the house is left, with the center path starting to degrade too.

Adherence to action conditioning
As the footage covers a large map and therefore does not present multiple possible actions sequences given a similar world state, I suspect the model can roughly memorize the preceding frames and ignores the actions. As a result, rollouts are minimally different when conditioned on forward or no movement. I have some ideas to try and remedy this, which I hope to get to soon!