Can diffusion transformers do in-silico neuroscience?
General ·In a new preprint, we train models to generate neural (FMRI) time series. We evaluate on hundreds of unseen task conditions and check if predicted experimental manipulations match reality.
We use a transformer setup which allows for conditioning per time step by injecting conditioning tokens directly in context. For each time step, we include compositional language tokens of task descriptions as well as optional spatial priors to aid out-of-distribution generation. This allows us to specify task structure flexibly.
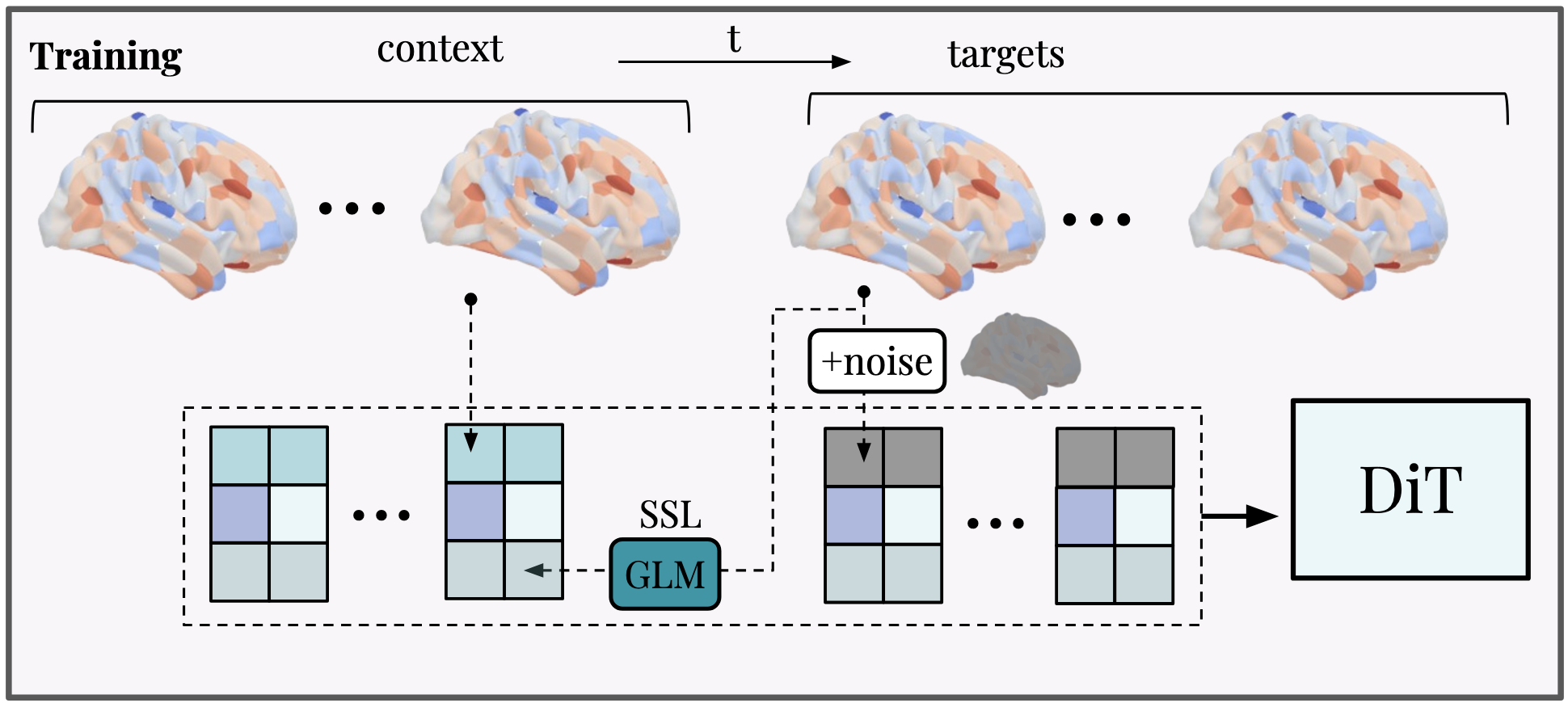
Some results:
We find that the model enables counterfactual generation (B,C,D), learns the brain’s hemodynamic response function (C), and captures repetition inhibition (D) - a well established finding in neuroscience.

Next, we generate time series for unseen tasks and recover activation maps. We find that using compositional language conditioning alone can perform surprisingly well (correlations with real of 0.35-0.60 depending on setup).
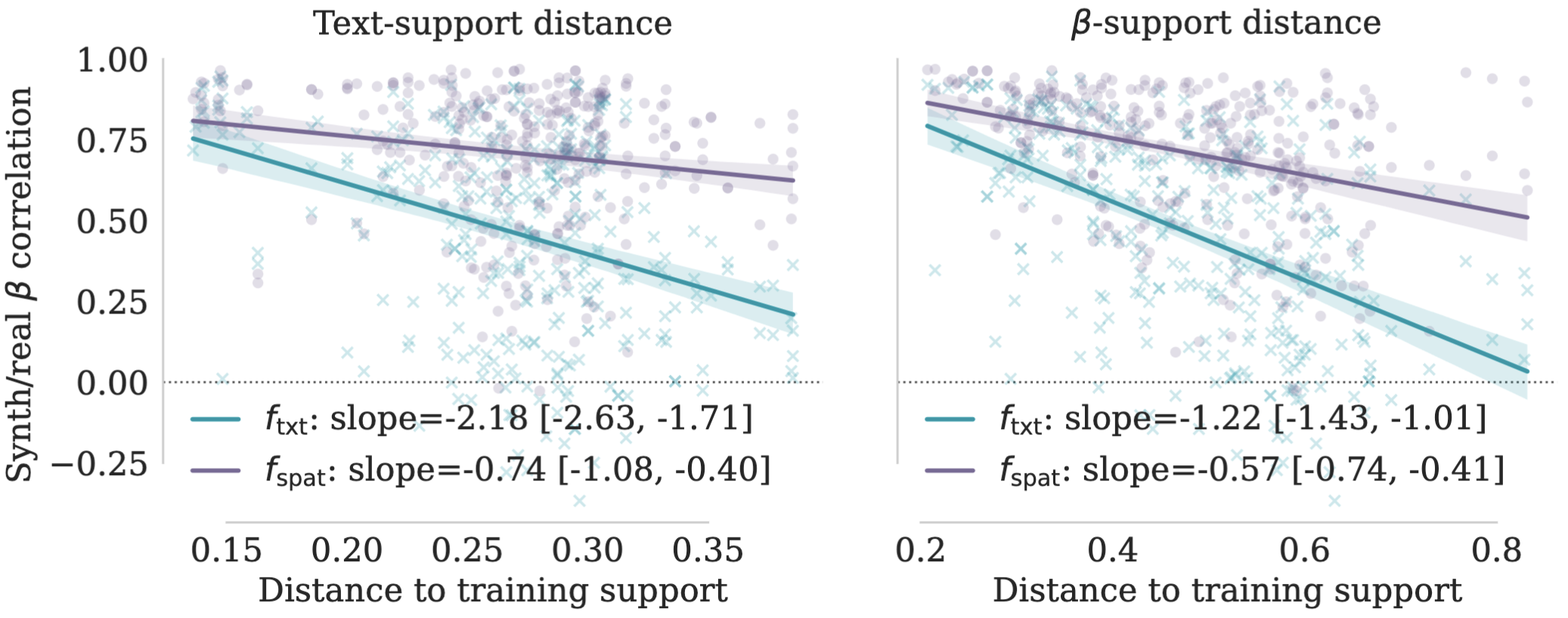
However, OOD performance expectedly degrades with distance to the training support. We therefore train the model to use optional spatial priors in a self-supervised manner. These priors are defined per event or response, can be obtained from existing datasets, and then re-composed for counterfactual experiments.
We confirm that using spatial priors yield better OOD performance further from the training support where language-only conditioning struggles (increasing correlations with real up to 0.88).
We quantify training support distance in terms of both spatial activation maps and language embeddings of task descriptions, both showing distinct degradation profiles.
This constitutes just a first step towards in silico experimental design but already works surprisingly well, with tons of open paths for improvements!